
Lilia ZIANE KHODJA (ANEO), Damien DUBUC (ANEO), Florent DE MARTIN (BRGM), Faïza BOULAHYA (BRGM), Steve MESSENGER (AWS), Gilles TOURPE (AWS), Diego BAILON HUMPERT (Intel), Loubna WORTLEY (Intel)

The Bureau de Recherches Géologiques et Minières (BRGM, French Geological Survey) is France’s leading public institution for Earth Science applications for the management of surface and sub-surface resources with a view to sustainable development. Under partnerships with numerous public and private stakeholders, it focuses on scientific research, providing scientifically-validated information to support public policy development and international cooperation.
To this end, BRGM needs to carry out high performance computing (HPC) simulations to assess various quantities of interest for public policy, such as sea level rise, seismic hazard or building vulnerability. For example, large-scale, physics-based earthquake scenarios are performed to assess seismic hazard as well as to quantify their degree of confidence with respect to the epistemic or aleatoric uncertainties. This approach requires tremendous computing resources that are generally provided by national (Tier-1) or European (Tier-0) infrastructures.
This post reports on the performance of EFISPEC3D, BRGM’s HPC application to compute earthquake scenarios on AWS.
EFISPEC3D is a scientific computer program that solves the three-dimensional equations of motion using a continuous Galerkin spectral finite element method. The code is parallelized using the Message Passing Interface (MPI).
“EFISPEC3D is optimized to scale over several thousands of cores for standard mesh size (e.g., 2 millions of spectral elements) thanks to its non-blocking communication scheme and its three levels of MPI communicators. The performance results depicted hereafter using a mesh of 1,906,624 spectral elements partitioned onto 27036 physical cores show a fair scaling down to 70 spectral elements per physical cores.” EFISPEC3D is used in different areas, such as seismic hazard assessment for critical industrial facilities like nuclear power plants, urgent computing, sensitivity analysis via Machine Learning or seismic wave propagation in complex geological medium (e.g., sedimentary valleys, volcanoes, etc.).
EFISPEC3D is developed by the French Geological Survey (BRGM) since 2009 in collaboration with Intel Corp, the Institute of Earth Sciences (ISTerre), and the Fundamental Computer Sciences Laboratory of Orléans (LIFO). It has been and is still part of several research projects funded by the French National Research Agency (ANR).




Different views of the mesh of the test case n°2 designed with two levels of refinements: one from 315 m to 105 m and one from 105 m to 35 m in order to account for seismic wavelengths measuring at least 35 meters. Within the contour of the basin, the mesh is refined over a constant depth that includes the bottommost point of the sedimentary basin under investigation. The mesh contains 7,053,889 unstructured hexahedral elements (approximately 1.4 billion degrees of freedom) on which the weak form of the equations of motion is solved.
Performance Results
The interest here is to present the use of the AWS services to carry out BRGM’s prediction simulations. A typical simulation lasting about 300 days on a single core will be run in 25 min on AWS Cloud, with using 27k physical cores and no hyperthreading.
AWS has made available several types of Amazon Elastic Compute Cloud (Amazon EC2) Intel-based instances. The 27k cores used for this performance report are based on c5n.18xlarge instances with Intel® Xeon® Platinum 8000 Series processor (Skylake-SP) with a frequency of 3.5GHz as well as m5zn.12xlarge instances powered by custom Intel® Xeon® Scalable 2nd generation processors (Cascade Lake) at 4.5GHz. Both Amazon c5n and m5zn instances use Elastic Fabric Adapter (EFA) to support inter-nodes communication. The two different types of instances were chosen as they offer different balances of cost/performance.
| Instance | Processor | vCPU | RAM (GiB) | Networks (Gbps) |
| c5n.18xlarge | Skylake-SP | 72 | 192 | 100 |
| m5zn.12xlarge | Cascade-Lake | 48 | 192 | 100 |
Strong scaling simulations
In the first experiments, we test the strong scaling of the EFISPEC3D application on AWS c5n.18xlarge and m5zn.12xlarge instances.
The following script describes an example of a batch script to perform a simulation on 16 384 cores of c5n.x18large instances:
#!/bin/bash
#SBATCH --account=account-strong-scaling-16384
#SBATCH --job-name=string-scaling-16384
#SBATCH --partition=batch-c5n
#SBATCH --hint=nomultithread
#SBATCH --mem-per-cpu=2048M
#SBATCH --nodes=456
#SBATCH --ntasks=16384
#SBATCH --ntasks-per-node=36
#SBATCH --ntasks-per-core=1
#SBATCH --output=string-scaling-16384-%x_%j.out
ulimit -s unlimited
mpiexec.hydra -n 16384 /fsx/applications/EFISPEC3D-c5n-18xlarge/TEST-1-STRONG-SCALING/EFISPEC3d-ASYNC/bin/efispec3d_1.1_avx.exe
A mesh of about 2 million hexahedra, about 77GiB RAM, is analyzed on a single physical core to 27036 physical cores.
| Number of cores | Number of instances | Average number of hexahedra per physical core | Average RAM per core (Mo) | Elapsed time for initialization |
| 1 | 1 | 1906624 | 77145.555 | 181.56 s |
| 32 | 1 | 59582 | 2420.925 | 29.62 s |
| 64 | 2 | 26480 | 1077.098 | 25.91 s |
| 128 | 4 | 13240 | 539.555 | 28.89 s |
| 256 | 8 | 6620 | 270.070 | 39.14 s |
| 512 | 15 | 3530 | 144.265 | 37.57 s |
| 1024 | 29 | 1826 | 74.870 | 61.39 s |
| 2048 | 57 | 930 | 38.236 | 97.45 s |
| 4096 | 114 | 464 | 19.192 | 182.35 s |
| 8192 | 228 | 233 | 9.700 | 442.14 s |
| 16384 | 456 | 117 | 4.898 | 154.01 s |
| 27036 | 751 | 71 | 2.988 | 276.20 s |
The following tables (Table 2, Table 3, Table 4 and Table 5) present the strong scaling of EFISPEC3D on C5n and M5zn instances:
| Number of cores | Blocking communications | Non-blocking communications |
| 1 | 2542.38 s | 2522.54 s |
| 32 | 92.13 s | 106.09 s |
| 64 | 45.19 s | 47.50 s |
| 128 | 22.79 s | 24.93 s |
| 256 | 12.18 s | 12.51 s |
| 512 | 6.66 s | 6.63 s |
| 1024 | 3.57 s | 3.34 s |
| 2048 | 2.17 s | 1.60 s |
| 4096 | 1.43 s | 0.79 s |
| 8192 | 1.74 s | 0.40 s |
| 16384 | – | 0.20 s |
| 27036 | – | 0.14 s |
| Number of cores | Blocking communications | Non-blocking communications |
| 1 | 1.0x | 1.0x |
| 32 | 27.59x | 23.78x |
| 64 | 56.26x | 53.10x |
| 128 | 111.56x | 101.19x |
| 256 | 208.79x | 201.67x |
| 512 | 381.94x | 380.59x |
| 1024 | 711.14x | 754.92x |
| 2048 | 1171.72x | 1576.72x |
| 4096 | 1782.18x | 3187.30x |
| 8192 | 1457.32x | 6339.85x |
| 16384 | – | 12484.81x |
| 27036 | – | 18030.57x |
| Number of cores | Number of instances | Blocking communications | Non-blocking communications |
| 1 | 1 | 2026.03 s | 2027.19 s |
| 32 | 2 | 50.25 s | 54.49 s |
| 64 | 3 | 33.28 s | 36.82 s |
| 128 | 6 | 16.77 s | 17.70 s |
| 256 | 11 | 9.47 s | 9.56 s |
| 512 | 22 | 4.77 s | 4.91 s |
| 1024 | 43 | 2.98 s | 2.49 s |
| Number of cores | Blocking communications | Non-blocking communications |
| 32 | 40.31x | 37.20x |
| 64 | 60.88x | 55.06x |
| 128 | 120.82x | 114.51x |
| 256 | 213.94x | 211.99x |
| 512 | 424.32x | 413.09x |
| 1024 | 680.74x | 812.20x |
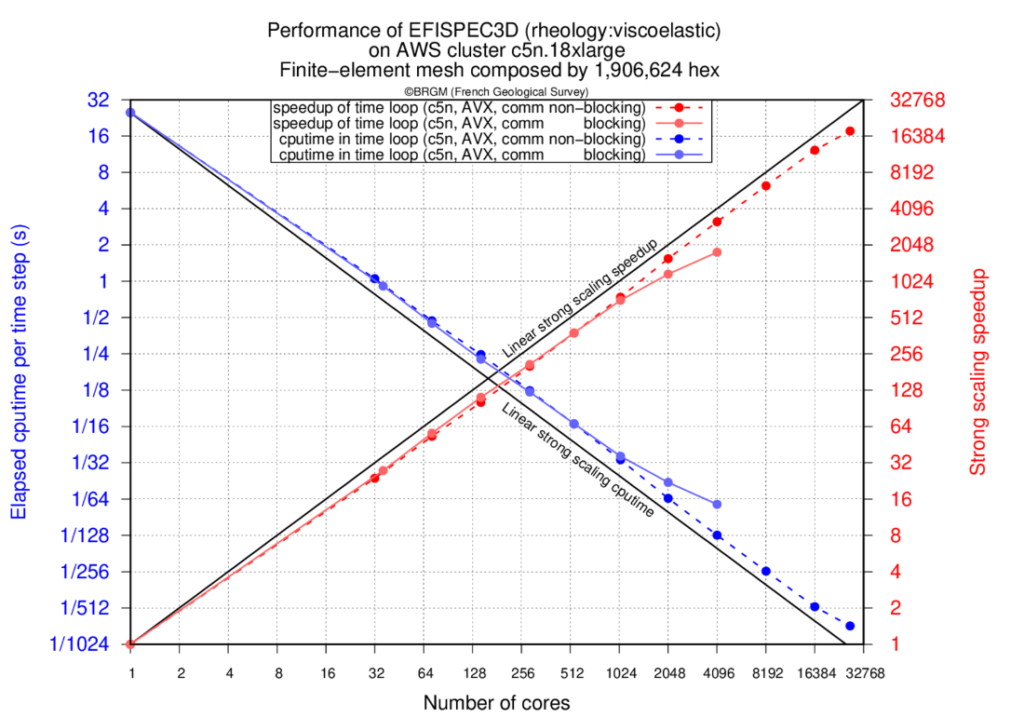
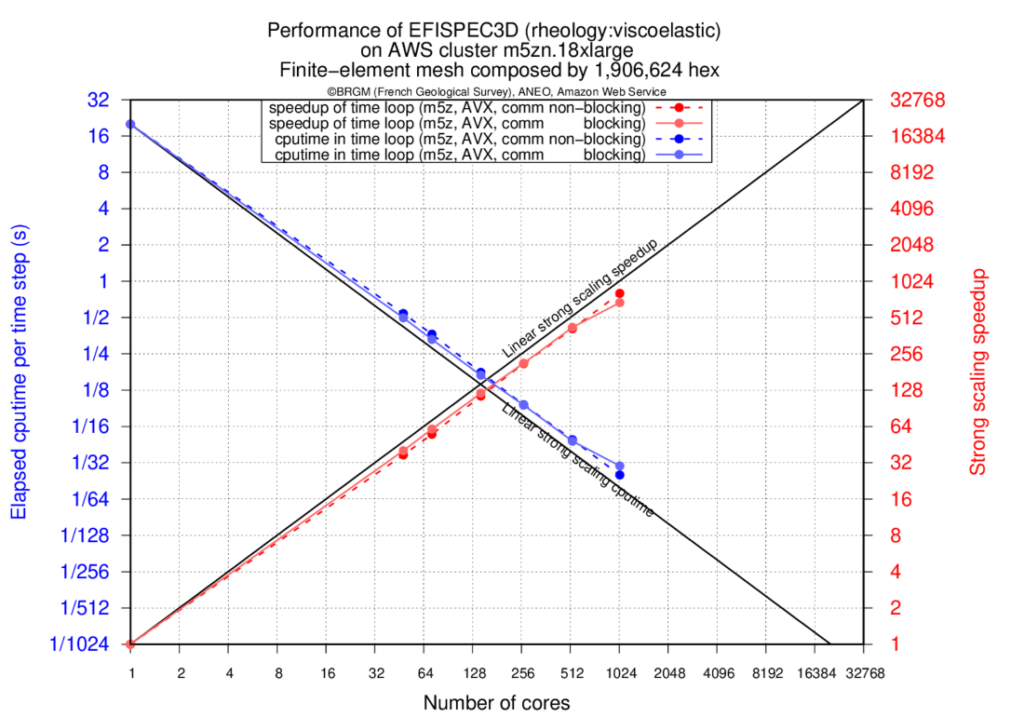
The results present the elapsed times for the time loop computation (in seconds) of EFISPEC3D using blocking or non-blocking communications, and the achieved speedups with respect to the simulation made on a single physical core. We can notice that the strong scaling on the cluster of AWS with EFA is 67% at 27036 cores, more particularly for the non-blocking communications version for which a speedup of 18030 is reached on 27036 physical cores (see Figure 1). Such a speedup allows to compute a standard earthquake simulation in about 25 minutes instead of 300 days on a single core.
When blocking communications are used, we can see the drop in performance around 2048 cores due to the incompressible time of send receive MPI calls. By overlapping communications with computations, the drop of performance is pushed back until 27036 cores.
7M hexahedra simulations
During this second experiment, we enabled reading and writing to the Amazon FSx for Lustre file system in the EFISPEC3D application as the application uses data writing via Intel MPI. We then chose to check the performance of Amazon FSx for Lustre.
The objective was to test the performance of writing results to a file system when 2048 tasks write results to the file system at the same time. For this test, we have used a cluster of 57 c5n.18xlarge instances (total of 2052 cores).
The execution of the application generates 2TB of data mostly condensed in a single file. The performance configuration of the file system is based on two main parameters: the block size factor and the stripping factor. They are respectively the data packet size to write and the number of packets to write simultaneously by the application. The configuration of the file system makes it possible to calibrate the optimal writing to disk in adequacy with the size of writing by the application and the number of writing lines authorized by the file system.
To allow performance analysis for several file system configurations, we have reduced the file size to 206GB. This procedure allowed us to evaluate many more different configurations of the Amazon FSx for Lustre file system while preserving the reliability of the performance results obtained.
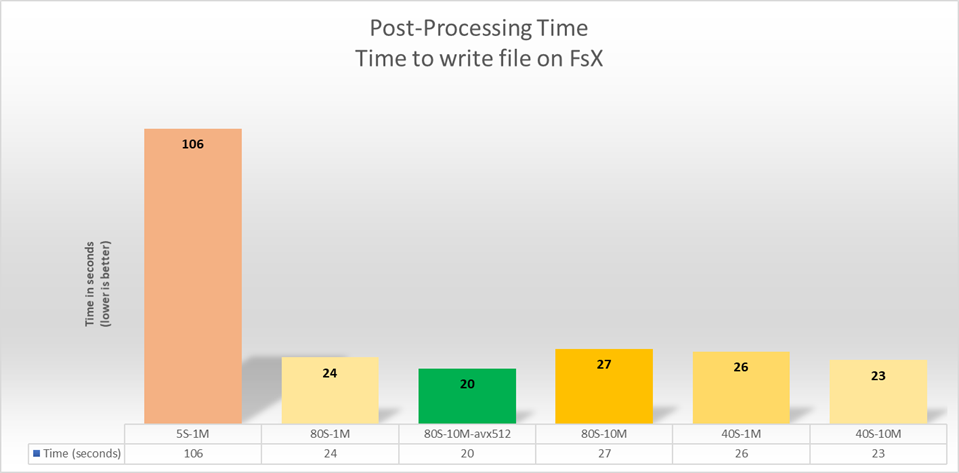
Impact of file system parameters. Lustre on the bandwidth measured for the reading phase
of the data (206GB). The stripe size varies from 1MB to 10MB and the striping factor varies from 5 to 80.
In the chart Figure 3, each stick represents one execution with different configuration of Amazon FSx for Lustre parameters. For example, 5S – 1M means the test was calibrated with 5 Stripes factor and 1 Megabyte as size of bloc of data.
TheSE tests were run using a 96TiB FSx for Lustre volume with 80 OSDs. The “Scratch 2” deployment type or FSx for Lustre was used. This FS offers a theoretical performance of 200MBs per TB + 1.3GB/s of burst bandwidth. The file system as deployed had a baseline performance of 16GB/s with burst capability of 104GB/s
Following these six executions, we notice that the best performances will be reached with EFISPEC3D when we set the file system with a stripes factor of 80 and block sizes of 10 Megabytes.
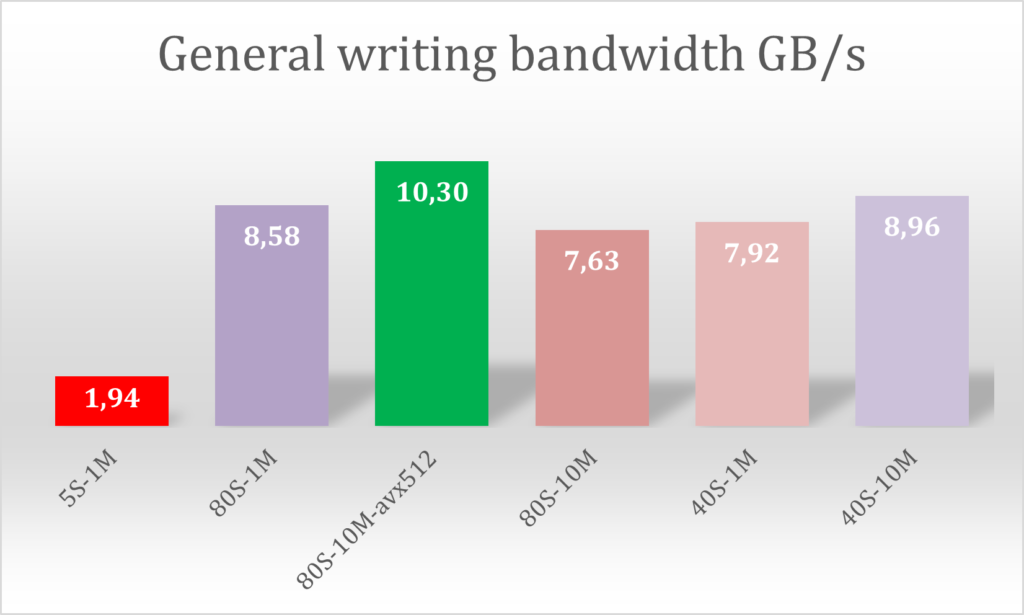
During the post processing phases of the EFISPEC3D application, the bandwidth went up to 10.3 GB/s to write a 206 GB result file.
Public cost study to 7M execution
We studied the cost of execution of the EFISPEC3D application on the simulation of 7 mega hexahedra. Based on the public prices of AWS proposed in the US Virginia Region.
As a reminder, the selected infrastructure is based on 2048 physical cores of the c5n.18xlarge instance and its 72 vCPUs of Intel® Xeon® Platinium processor. This means that we were able to start 57 instances of c5n.18xlarge in the same Region, namely the us-east-1 Region.
The total cost of these instances for 25 minutes comes to a public price of $93. In the chosen infrastructure we also use the FSx file system for $30 per day per deployed cluster for 3.6TB of storage.
In total, the cost of the cluster for this type of execution comes to $123 public price for an application execution during 25 minutes with 57 instances of c5n.18xlarge.
Conclusion
During the R&D and benchmarking phase, we were able to see how easy it is to deploy, install, and configure our HPC environment using AWS ParallelCluster, an AWS-supported open source cluster management tool that makes it easy for you to deploy and manage High Performance Computing (HPC) clusters on AWS. We have also seen how quickly C5n instances are available in all AWS Regions across the globe. The M5zn instances are quite different in a number of respects. They have fewer faster cores and are based on Intel Cascade Lake architecture. Over 400 different instance types are available on AWS. As always with HPC applications there is no substitutes for testing the real application and data to see which systems offer the best blend of cost performance for any given application.
During the strong scaling tests, we were able to observe very good performance of the EFISPEC3D application which demonstrates the power of the C5n and M5zn servers for the HPC world.
Concerning the Amazon FSx for Lustre file system, we reached a bandwidth higher than 10GB/s which more than met the requirements of our application with intensive disk writing by all compute nodes.
EFISPEC3d is featured in a HPC Workshop. The workshop guides the user through the process of deploying a HPC cluster and running the EFISPEC3D software. It can be found at this location:
https://hpc.news/efispec3dworkshop
More information about EFISPEC3D can be found here:



