
TL;DR
- ArmoniK est une plateforme open source de calcul haute performance et haut débit qui abstrait la complexité du déploiement d’applications distribuées.
- En prenant en charge l’ordonnancement des tâches, la gestion des données et la tolérance aux pannes, ArmoniK permet une utilisation efficace des ressources, même sous de fortes charges.
- Les benchmarks montrent une utilisation des workers allant jusqu’à 99,3 % pour des tâches d’une seconde et un débit d’environ 4 500 tâches par seconde pour des tâches sans calcul, avec jusqu’à 2 000 task handlers.
- Des tests de montée en charge avec jusqu’à 2 000 workers traitant 10 millions de tâches démontrent la robustesse de la plateforme, tandis que son intégration étroite avec les services AWS (EKS, S3, ElastiCache et MQ) garantit des opérations fiables et économiquement efficaces.
- Les benchmarks à plus grande échelle (au-delà de 2 000 workers) ont été reportés pour des raisons de coûts et de quotas ; un article de suivi présentera ces résultats avec une reproductibilité complète.
Introduction
Dans le paysage informatique dynamique d’aujourd’hui, les organisations ne recherchent pas seulement une puissance de calcul massive, mais aussi une orchestration fluide des ressources distribuées. Si les plateformes cloud fournissent le matériel nécessaire, le véritable défi réside dans la gestion des charges de travail distribuées : coordination de l’ordonnancement des tâches, efficacité des transferts de données et maintien d’une tolérance aux pannes robuste sur des infrastructures hétérogènes.
ArmoniK répond directement à ces défis en abstrayant la complexité du calcul distribué. En automatisant des processus critiques tels que l’ordonnancement des tâches, l’allocation des ressources et la reprise après incident, la plateforme simplifie à la fois le développement et le déploiement des applications. Cette approche innovante permet aux développeurs de se concentrer sur les fonctionnalités métier et l’innovation, tout en optimisant les performances et la scalabilité dans les environnements modernes.
Dans cet article, nous explorons les performances et la capacité de montée en charge d’ArmoniK, en particulier dans le cadre de son intégration avec AWS. Nous abordons des fonctionnalités clés comme la distribution de graphes de tâches, la flexibilité des langages, la tolérance aux pannes et le scaling élastique. Les benchmarks mettent en évidence une utilisation efficace des ressources, avec une forte occupation des workers et un débit élevé sous des charges importantes, notamment lors de tests impliquant jusqu’à 2 000 task handlers traitant 10 millions de tâches.
Nous verrons également comment l’intégration d’ArmoniK avec les services AWS améliore les performances, la scalabilité et la fiabilité. À l’issue de cette lecture, vous aurez une vision claire des capacités d’ArmoniK et de son potentiel pour optimiser le calcul haute performance dans le cloud.
Les enjeux étant désormais posés et ArmoniK présenté comme la solution, explorons ce qui fait réellement fonctionner cette plateforme.
ArmoniK : une orchestration pour l’ère moderne du calcul
ArmoniK est une plateforme open source conçue pour répondre aux besoins croissants du calcul haute performance (HPC) et haut débit (HTC) sur des infrastructures hétérogènes [1]. En tant qu’orchestrateur de calcul, ArmoniK simplifie le développement et le déploiement d’applications distribuées en masquant la complexité de l’ordonnancement des tâches, de la gestion des données et de la tolérance aux pannes [2].
Au cœur de la plateforme, ArmoniK permet aux développeurs de se concentrer sur la logique applicative sans se soucier des détails d’exécution distribuée. La plateforme gère automatiquement la distribution des tâches, l’allocation des ressources et la reprise après échec, garantissant des performances fiables même dans des environnements dynamiques.
Après cette vue d’ensemble, intéressons-nous aux fonctionnalités clés qui donnent à ArmoniK toute sa puissance.
Fonctionnalités clés d’ArmoniK
- Distribution de graphes de tâches : ArmoniK distribue dynamiquement les graphes de tâches et leurs données associées sur les ressources disponibles. Les utilisateurs peuvent définir des partitions dans ces graphes afin de spécifier quels sous-graphes utilisent quelles machines et configurations (CPU, GPU, TPU, RAM, instances préemptibles, etc.). Une partition est une division logique qui permet d’optimiser l’allocation des ressources, d’isoler les charges de travail et d’améliorer la flexibilité sans modifier le code applicatif.
- Gestion des données : ArmoniK gère efficacement les données dans les systèmes distribués — un aspect souvent négligé par d’autres solutions — ce qui améliore les performances et la fiabilité.
- Flexibilité des langages : Des SDK sont disponibles pour plusieurs langages (C++, Python, Rust, C#, Java), facilitant l’intégration avec des bases de code existantes.
- Tolérance aux pannes : Des mécanismes intégrés détectent automatiquement les défaillances et assurent la reprise, garantissant la résilience des calculs.
- Scalabilité élastique : La plateforme s’adapte dynamiquement aux variations de charge, en augmentant ou en réduisant les ressources selon les besoins.
En prenant en charge ces responsabilités, ArmoniK permet aux développeurs de se concentrer sur la logique métier tandis que la plateforme gère la complexité du calcul distribué, y compris l’allocation des ressources et la gestion des données.
Ces fonctionnalités illustrent la polyvalence d’ArmoniK. Passons maintenant à la définition de certains termes techniques utilisés dans la suite de l’article.
Définitions
- Batch Size (taille de lot) : nombre de tâches regroupées pour la soumission.
- Itération : un cycle d’exécution dans un scénario de test.
- Temps de soumission : temps nécessaire pour envoyer les tâches au plan de contrôle.
- Temps de traitement : durée requise pour compléter les tâches après leur soumission.
- Temps total : somme des temps de soumission et de traitement (latence de bout en bout).
- Débit (Throughput) : nombre de tâches traitées par seconde.
- Session : conteneur logique regroupant les tâches et les données associées (statut, résultats, erreurs), avec support de la reprise et de l’annulation.
- Partition : regroupement logique de tâches et de ressources permettant d’assigner des configurations matérielles spécifiques et d’isoler les charges de travail.
- Worker : service gRPC fourni par l’utilisateur qui reçoit et exécute les tâches envoyées par l’agent ; il représente le code utilisateur.
Maintenant que la terminologie est claire, examinons comment les performances d’ArmoniK sont évaluées de manière rigoureuse.
Méthodologie de benchmarking
Nous avons développé un framework de test complet simulant des charges de travail réalistes. L’évaluation se concentre sur trois indicateurs clés :
- Efficacité : capacité d’ArmoniK à utiliser efficacement les ressources allouées.
- Débit : vitesse de traitement des tâches.
- Scalabilité : évolution des performances lorsque les ressources passent de 120 à 2 000 workers.
La configuration initiale utilise 120 workers (chacun disposant de 1 vCPU et 1 Gio de RAM), répartis sur 16 clients. Les charges de travail sont ajustées dynamiquement afin de simuler des scénarios allant de 1 million à 10 millions de tâches. En faisant varier un seul paramètre à la fois — soit la taille de la charge de travail, soit le nombre de workers — nous isolons et analysons l’impact sur les performances globales. Cette approche garantit une répartition contrôlée de la charge de calcul tout en maintenant un environnement d’exécution réaliste.
La stratégie de test commence par la mise en place de l’environnement et l’allocation des workers nécessaires. Une fois le système configuré, le benchmark est lancé en exécutant des jobs parallèles, en démarrant avec 1 million de tâches réparties équitablement entre les 16 clients. Au fur et à mesure de l’avancement des tests, la charge de travail est progressivement augmentée en modifiant le nombre de tâches assignées à chaque client, tout en adaptant le nombre de workers en conséquence. L’évaluation couvre les scénarios suivants, conçus pour analyser de manière systématique l’impact des variations de charge et du nombre de workers :
| Nombre de workers | Nombre de tâches (en millions) |
|---|---|
| 120 | 1 |
| 250 | 3 |
| 500 | 5 |
| 1000 | 7 |
| 2000 | 10 |
Afin de garantir une analyse précise, en cas de limitations du système, une seule variable à la fois — soit la charge de travail, soit le nombre de workers — est augmentée. Cette méthode permet d’examiner de manière isolée l’impact de chaque variable sur les performances du système.
Tout au long du processus de benchmarking, les métriques de performance sont enregistrées en continu, notamment le débit (throughput) et l’utilisation des ressources. Les données collectées sont ensuite analysées afin d’évaluer l’efficacité avec laquelle ArmoniK gère des charges de travail variables et monte en charge face à une demande croissante. Cette méthodologie fournit une évaluation structurée et complète des capacités d’ArmoniK dans différents scénarios de calcul.
Cette méthodologie prépare le terrain pour l’analyse des profils de tâches utilisés.
Profils de tâches
Pour représenter des conditions réelles variées, nous avons conçu plusieurs profils :
- Tâches indépendantes
- Tâches dépendantes (graphes d’exécution)
- Tâches sans calcul (zero-work) pour mesurer l’overhead d’orchestration
- Tâches d’une seconde, représentatives de charges réalistes d'une durée d'1 seconde
Ces profils permettent d’analyser finement le comportement du système.
Ordonnancement
Dans les environnements conteneurisés, l’agent d’ordonnancement d’ArmoniK joue un rôle central dans la gestion des tâches et la coordination de l’exécution des charges de travail. Fonctionnant aux côtés d’un worker au sein du même pod, l’agent utilise un algorithme spécialisé pour allouer efficacement les tâches. Il gère également les interactions avec la base de données, notamment la récupération et le stockage des données, ainsi que la génération de nouvelles tâches. En outre, l’agent prend en charge la gestion des erreurs en réessayant ou en re-soumettant les tâches ayant échoué. En confinant à la fois l’agent d’ordonnancement et le worker dans une même partition, le système conserve une architecture claire et structurée, améliorant ainsi l’efficacité et la fiabilité globales.
En abstrayant et en découplant les interactions entre l’orchestration et le stockage, l’agent d’ordonnancement permet aux utilisateurs de développer des applications avec ArmoniK sans se soucier du type de stockage sous-jacent. Cette flexibilité autorise une adaptation fluide à différents environnements sans modifier le code du worker ou du client, à l’exception des paramètres de partition ou de configuration des endpoints.
Le rôle de l’agent d’ordonnancement dans la gestion de ces fonctions critiques en fait un composant essentiel des architectures conteneurisées modernes, garantissant à la fois des performances robustes et une grande adaptabilité.
Après avoir examiné la manière dont les tâches sont ordonnancées, analysons maintenant la réactivité du système en évaluant sa latence.
Test de la latence d’ArmoniK
Afin d’évaluer de manière isolée l’overhead d’ordonnancement d’ArmoniK, nous avons utilisé des tâches sans calcul (zero-work tasks), c’est-à-dire des tâches qui retournent un résultat constant sans effectuer de calcul. Cette approche élimine le bruit lié au traitement et met en évidence la latence introduite par le plan de contrôle, la gestion des files d’attente et les mécanismes d’allocation des workers.Nous avons simulé trois modes de soumission couramment observés en production. Le premier scénario soumet les tâches individuellement, représentant des charges de travail fines. Les deuxième et troisième scénarios regroupent les tâches en lots de 10 et 100 respectivement. Pour chaque scénario, nous avons mesuré le temps de soumission, le temps de traitement et la latence globale de bout en bout (du lancement du job jusqu’au retour de l’ensemble des résultats).
Les résultats ont été visualisés sous forme de fonctions de distribution cumulée (CDF), avec l’axe des abscisses représentant la latence et l’axe des ordonnées indiquant la fraction des tâches complétées dans ce délai. Les CDF montrent clairement que des lots plus importants réduisent l’overhead par tâche, confirmant qu’ArmoniK amortit efficacement les coûts fixes d’ordonnancement, même sous un débit élevé.
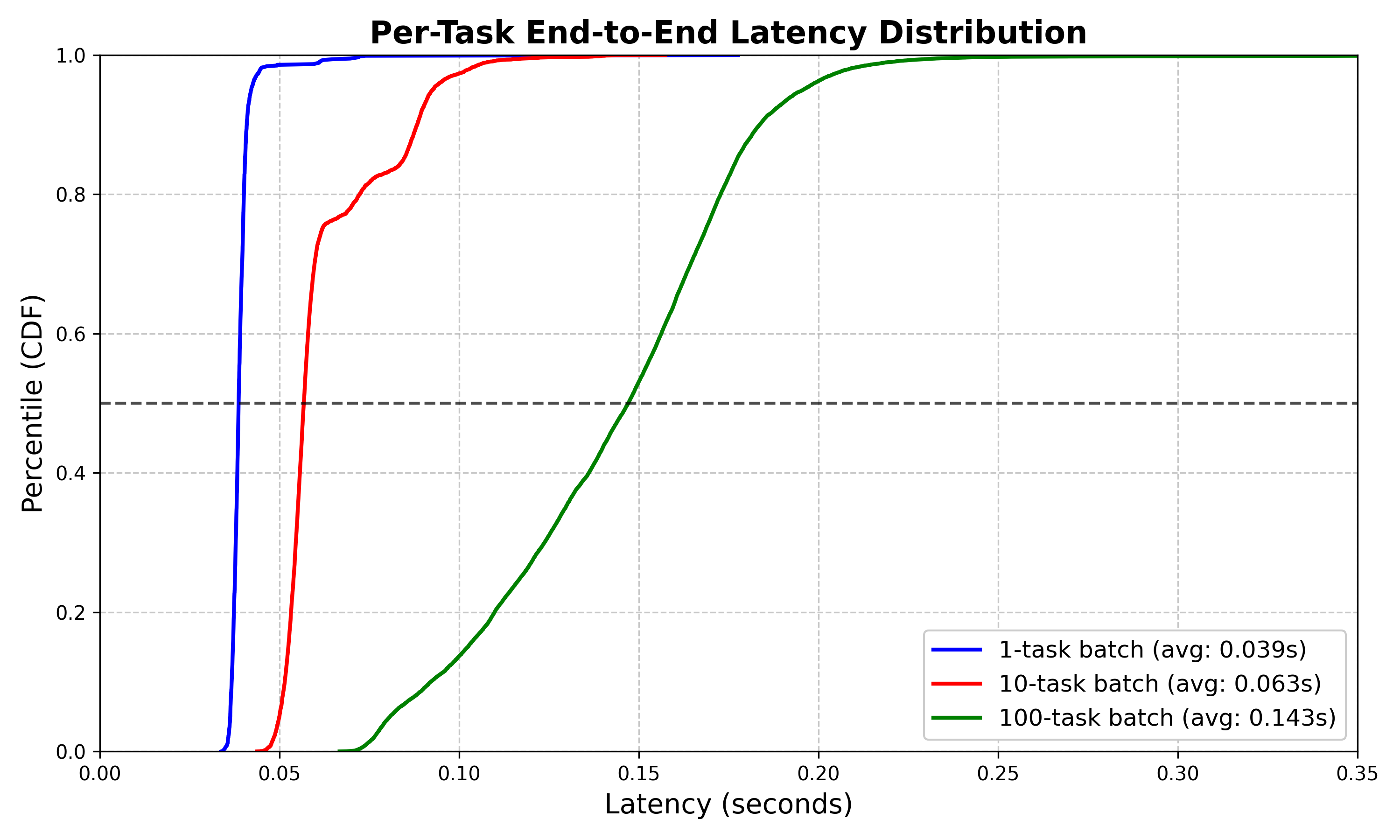
Figure 1 : La CDF montre que les tâches soumises individuellement se terminent en moyenne en environ 40 ms (presque toutes sous les 50 ms), que les lots de 10 tâches atteignent une moyenne d’environ 60 ms (la plupart sous les 70 ms), et que les lots de 100 tâches affichent une latence moyenne proche de 140 ms (presque toutes sous les 150 ms).
Sur cette figure, les lots unitaires se terminent en moyenne en 40 ms, avec quasiment toutes les tâches finalisées en moins de 50 ms. Les lots de dix tâches présentent une moyenne d’environ 60 ms, la majorité s’achevant avant 70 ms. Même avec des lots de 100 tâches, la latence de bout en bout moyenne reste proche de 140 ms, et presque toutes les tâches sont complétées en moins de 150 ms. Ces résultats illustrent qu’ArmoniK maintient non seulement un overhead faible quel que soit le mode de soumission, mais garantit également une latence acceptable et pratiquement imperceptible pour l’utilisateur. La latence de bout en bout demeure largement inférieure à un quart de seconde, même pour les lots volumineux, rendant la performance quasi instantanée du point de vue utilisateur.
Cette analyse de la latence nous apporte un éclairage précieux sur la réactivité du système et prépare le terrain pour l’étude de son efficacité dans le traitement de tâches de courte durée.
Efficacité avec des tâches courtes
ArmoniK démontre des capacités d’orchestration exceptionnelles lors du traitement de charges de travail de courte durée, un indicateur de performance clé pour les environnements de calcul à haut débit. Notre méthodologie de test s’appuie sur des tâches d’une seconde afin d’évaluer l’efficacité du système dans des conditions opérationnelles réalistes.Nous avons progressivement augmenté l’échelle de 1 à 2 000 workers exécutant des tâches standardisées d’une seconde, en surveillant attentivement les taux d’occupation des workers tout au long de chaque session de calcul. Les données collectées lors d’une session avec 2 000 workers mettent en évidence les performances remarquables d’ArmoniK.
L’efficacité étant désormais établie, passons au cœur du système : son architecture de distribution des tâches, élément clé à l’origine de ces résultats impressionnants.
Architecture de distribution des tâches
Cette efficacité repose sur une architecture optimisée :
- Transfert des tâches depuis la base persistante vers des files haute performance
- Polling des workers via une interface à faible latence
- Dispatch immédiat des tâches disponibles
- Retour rapide des résultats
- Requête immédiate de nouvelles tâches par les workers
Cette architecture constitue la colonne vertébrale des performances d’ArmoniK. Nous allons maintenant quantifier ces capacités à l’aide de métriques de performance spécifiques.
Analyse des performances
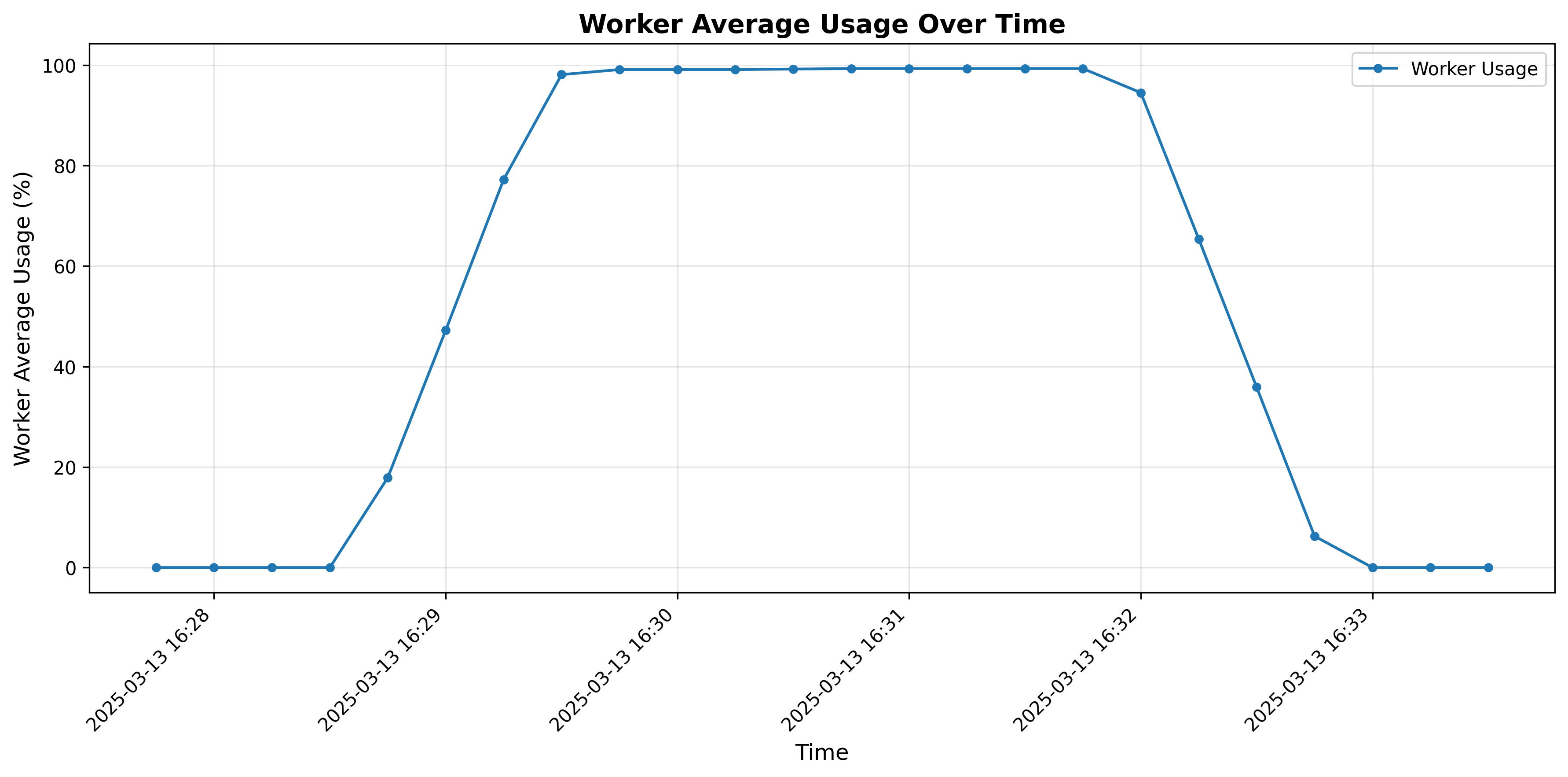
Figure 2 : Graphique de l’utilisation moyenne des workers pour 2000 workers
Le graphique d’utilisation des workers révèle trois phases distinctes :
- Phase d’initialisation rapide : L’utilisation des workers passe de 0 % à 98,1 % en seulement 45 secondes, démontrant les capacités efficaces d’ArmoniK à distribuer les tâches.
- Efficacité maximale soutenue : L’utilisation des workers se stabilise précisément à 99,3 %, maintenant ce niveau exceptionnel pendant plus de 2 minutes.
- Désactivation contrôlée : À mesure que la charge diminue, l’utilisation des workers décroît progressivement de 94,5 % à 0 %.

Figure 3 : Durée d’exécution des handlers de tâches et graphiques de débit durant une session de tâches d’une seconde
La figure 3 illustre les métriques de traitement des tâches d’une seconde, révélant un temps moyen d’exécution des tâches de 2,42 secondes — très proche du temps total d’exécution, ce qui indique un overhead d’ordonnancement minimal. Avec une utilisation des workers à 99,3 %, presque tout le temps de calcul est dédié au travail productif, ce qui se traduit par une optimisation de l’utilisation des ressources, une réduction des coûts et une accélération de l’achèvement des tâches.
Après avoir passé en revue ces métriques, nous concentrons désormais notre attention sur la manière dont l’efficacité et le débit collaborent pour maximiser la performance.
Analyse de l’efficacité
Le taux d’utilisation des workers de 99,3 % signifie que, pour 1 000 secondes de temps de calcul alloué, 993 secondes sont consacrées directement à l’exécution productive des tâches. Cette efficacité remarquablement élevée est obtenue malgré les défis inhérents au traitement de tâches de courte durée, où même un overhead d’ordonnancement minimal peut impacter significativement les taux d’utilisation.
Le déficit marginal d’efficacité de 0,7 % résulte de la latence inévitable entre l’acquisition des tâches et la transmission des résultats. Malgré cette contrainte, le système de distribution des tâches d’ArmoniK démontre des performances exceptionnelles, gérant les charges de travail avec un impact minimal sur l’efficacité globale.
Ce niveau d’efficacité se traduit directement par une optimisation de l’utilisation des ressources, une réduction des coûts opérationnels et une accélération des temps d’exécution des charges de travail intensives en calcul.
Avec l’efficacité et le débit désormais clairement définis, notre prochain sujet est la scalabilité — un facteur clé dans les environnements à forte demande actuels.
Débit
Le débit (throughput) est une métrique cruciale qui mesure la vitesse à laquelle un système peut traiter des tâches. Il est particulièrement important dans les environnements de production où un grand volume de tâches doit être géré efficacement pour répondre aux exigences opérationnelles. La capacité à traiter rapidement et efficacement les tâches est essentielle pour maintenir la productivité et garantir une utilisation optimale des ressources informatiques.
Tâches sans calcul (Zero-work-task)
Les capacités de débit d’ArmoniK sur les tâches sans calcul fournissent un aperçu de l’efficacité de l’ordonnancement de la plateforme. Les tâches sans calcul nous permettent de mesurer l’overhead d’orchestration sans la variabilité liée au temps de calcul réel.
Nos tests ont utilisé 2 000 workers avec 16 clients distribués soumettant simultanément environ 10 millions de tâches sans calcul. Cette configuration a permis de tester en profondeur les capacités d’ordonnancement du système sous une charge importante.
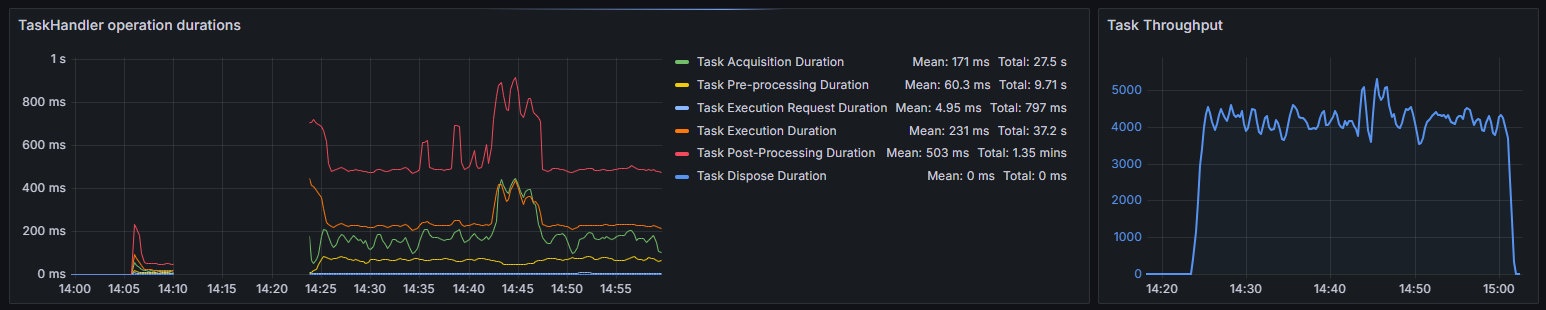
Figure 4 : Durée d’exécution des handlers de tâches et graphiques de débit pendant la session de tâches sans calcul
Les données de performance révèlent trois phases distinctes dans le cycle de traitement des tâches d’ArmoniK :
- Initialisation : Dès la soumission initiale, ArmoniK présente une phase de montée en charge d’environ 4 minutes avant d’atteindre un débit opérationnel. Cette période correspond au temps nécessaire pour initialiser les ressources et commencer le traitement distribué.
- Phase opérationnelle : En régime permanent, ArmoniK maintient un débit moyen d’environ 4 200 tâches par seconde, avec des pics dépassant 5 300 tâches par seconde. Le débit montre une certaine variabilité, mais reste constant sous une charge soutenue.
- Phase de terminaison : À mesure que les tâches sont terminées, le débit décroît progressivement, les tâches restantes étant traitées et les ressources libérées.
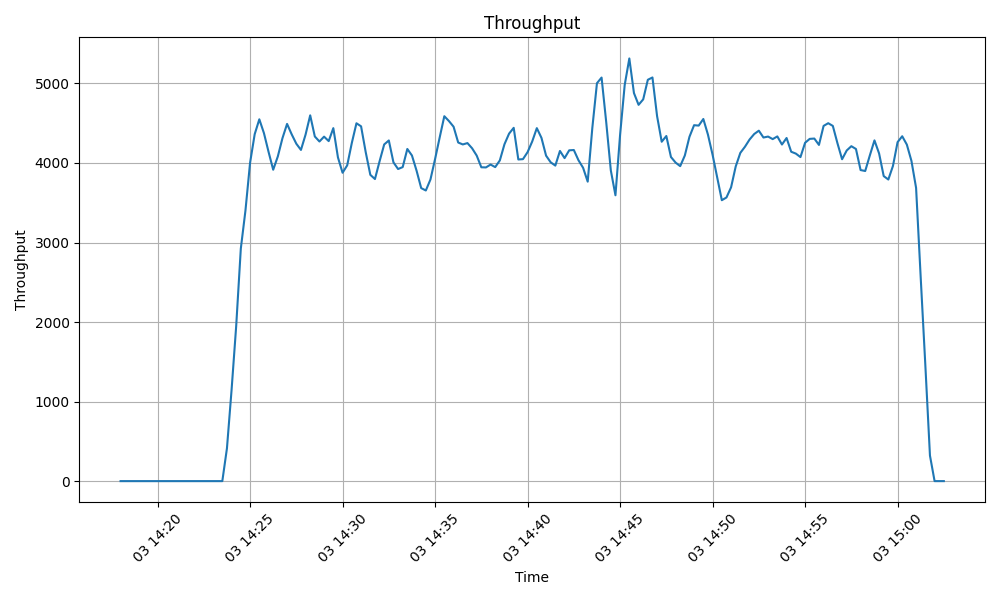
Figure 5 : Graphique du débit des tâches pendant la session de tâches sans calcul
Cette performance correspond à environ 15 millions de tâches traitées par heure, soit 360 millions de tâches en 24 heures. Pour les environnements d’entreprise ayant des besoins de calcul en production, cela signifie qu’ArmoniK peut traiter de lourdes charges de travail dans les fenêtres de production.
ArmoniK atteint ce débit élevé grâce au pipelining, où orchestration et calculs se chevauchent. Les workers demandent la tâche suivante avant d’avoir terminé la tâche en cours, minimisant ainsi le temps d’inactivité entre les tâches. Ce chevauchement est crucial pour obtenir une forte utilisation des workers, comme le démontre le taux de 99,3 % d’utilisation lors des tests avec tâches d’une seconde. Cette efficacité est possible grâce à ce chevauchement entre orchestration et calcul, garantissant que les workers sont constamment engagés dans le traitement des tâches.
Bien que les résultats indiquent une gestion efficace des charges de travail liées à l’ordonnancement et au calcul, des opportunités d’optimisation des performances existent, notamment dans les phases d’acquisition des tâches et de post-traitement où un overhead significatif a été observé.
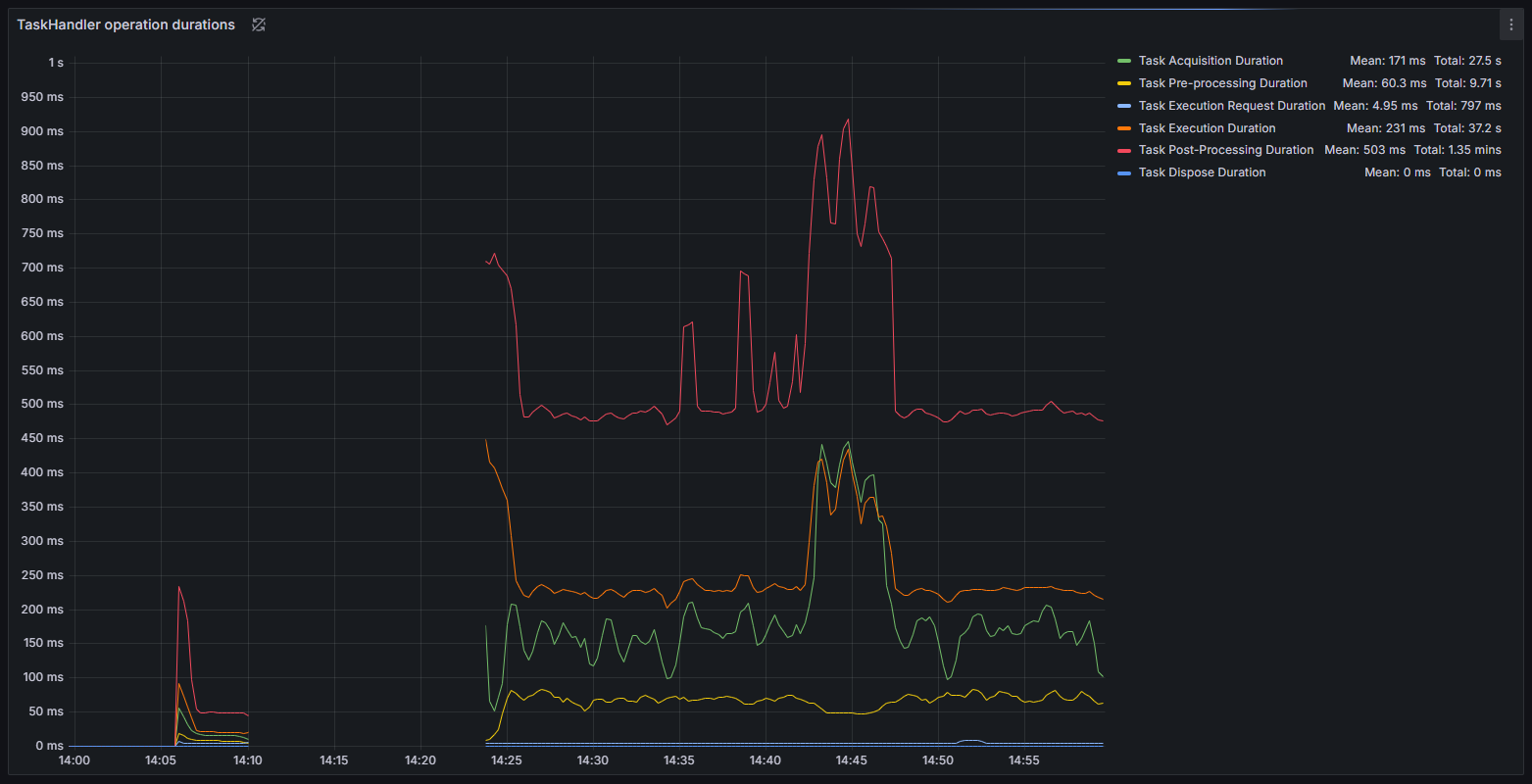
Figure 6 : Durée d’exécution des handlers de tâches pendant la session de tâches sans calcul
Scalabilité
La scalabilité est un aspect crucial des performances d’ArmoniK, déterminant sa capacité à gérer efficacement des charges de travail croissantes. Notre analyse évalue dans quelle mesure ArmoniK s’adapte à différentes configurations en mesurant ses performances avec un nombre variable de workers et de tâches. Nous nous concentrons sur la compréhension des points forts ainsi que des goulets d’étranglement qui apparaissent à mesure que le système évolue. Nous avons limité nos tests à 2 000 workers en raison des coûts (environ 13 000 $ pour les expériences présentées dans cet article) et réaliserons des benchmarks à plus grande échelle à l’avenir.
Nous avons évalué la scalabilité en augmentant systématiquement le nombre de workers et en mesurant le débit résultant. La charge de travail consistait en des tâches conçues pour simuler des besoins informatiques réels, chaque tâche nécessitant environ une seconde pour être exécutée. Nos résultats montrent que le débit s’améliore significativement avec plus de workers, doublant presque à chaque doublement des ressources. Cependant, à mesure que le nombre de workers augmente davantage, le taux d’amélioration ralentit, indiquant des rendements décroissants dus à la contention des ressources ou à l’overhead du système.
ArmoniK affiche une scalabilité quasi linéaire pour les tâches indépendantes, les distribuant efficacement avec un overhead de coordination minimal. Cependant, pour des charges de travail comportant des dépendances entre tâches, la scalabilité est légèrement moins efficace en raison de la coordination supplémentaire requise. Néanmoins, le débit continue d’augmenter avec l’ajout de workers, et des améliorations dans la gestion des dépendances pourraient encore améliorer les performances.
À très haut nombre de workers, des inefficacités telles que l’overhead d’ordonnancement et la latence de communication deviennent perceptibles, impactant la performance globale. Malgré ces défis, ArmoniK démontre une scalabilité robuste, notamment pour les tâches indépendantes, avec un débit suivant de près l’augmentation des ressources.
Voici un exemple de session de scalabilité utilisant des tâches d’une seconde :
| #Workers | #Tâches | Débit (Throughput) |
|---|---|---|
| 1 | 200 | 1 |
| 120 | 50 k | 119 |
| 250 | 100 k | 248 |
| 500 | 100 k | 496 |
| 1000 | 200 k | 992 |
| 2000 | 400 k | 1980 |
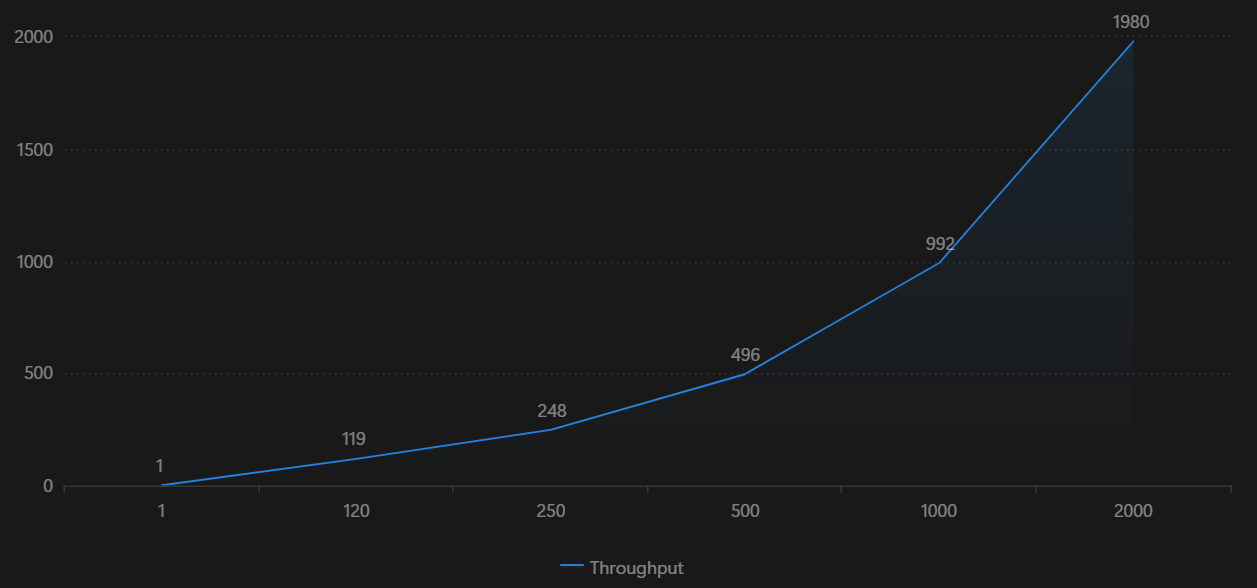
Figure 7 : Graphique de scalabilité pour des tâches d’une seconde, de 1 à 2000 workers
Ce tableau illustre comment le débit d’ArmoniK évolue en fonction du nombre de workers, offrant une vue claire de ses capacités de performance sous différentes charges de travail. L’analyse met en évidence la scalabilité efficace d’ArmoniK tout en identifiant des pistes d’optimisation, notamment dans la gestion des dépendances entre tâches.
Après avoir établi la scalabilité, il est temps de voir comment ArmoniK tire parti de la puissance d’AWS pour renforcer encore ses capacités.
Pourquoi les benchmarks à plus grande échelle ont été reportés
Les tests au-delà de 2 000 workers ont été volontairement différés dans cet article afin de garantir la fiabilité, la reproductibilité et la maîtrise des coûts. Les principales raisons sont les suivantes :
- Coûts et quotas : Les très grands clusters EKS, ainsi que leurs files d’attente, caches et stockages, augmentent significativement les coûts et peuvent atteindre les quotas ou limites de service AWS, compliquant la réalisation de mesures cohérentes entre différentes exécutions.
- Reproductibilité : La publication de l’infrastructure en tant que code, des tableaux de bord et des jeux de données bruts nécessite une validation supplémentaire pour s’assurer que d’autres peuvent reproduire les résultats de manière fiable.
Ce qui est prévu ensuite (dans un article à venir) :
- Des tests à plus grande échelle (5 000 à 10 000 workers), incluant des scénarios multi-AZ et exploratoires multi-régions.
- Des graphes acycliques dirigés (DAG) fortement dépendants et des charges de travail aux durées mixtes (de moins de 100 ms à plusieurs minutes).
Intégration avec AWS
ArmoniK s’intègre parfaitement à AWS pour offrir une plateforme d’orchestration évolutive et économique. Fonctionnant sur Amazon EKS, la plateforme bénéficie d’un environnement Kubernetes géré qui simplifie les déploiements en automatisant la provision des nœuds, les mises à jour et les configurations de sécurité. Cela garantit une haute disponibilité sur plusieurs zones de disponibilité et réduit la charge opérationnelle des équipes de déploiement.
La solution utilise des configurations Terraform flexibles pour prendre en charge à la fois les instances à la demande et les instances spot, ce qui lui permet d’allouer dynamiquement les ressources en fonction des besoins de la charge de travail. À mesure que les ressources de calcul doublent, le débit évolue presque proportionnellement, ce qui confirme l’efficacité du système dans la gestion des charges croissantes tout en maîtrisant les coûts.
En plus de l’infrastructure de calcul principale, ArmoniK exploite plusieurs services AWS gérés clés pour rationaliser les opérations. Amazon S3 est utilisé pour un stockage d’objets fiable et évolutif des entrées et sorties des tâches. Pour la messagerie, Amazon MQ et SQS assurent que l’orchestration des tâches reste robuste et réactive même sous de fortes charges.
Dans l’ensemble, cette intégration profonde avec AWS améliore non seulement les performances et la scalabilité, mais offre également la fiabilité et la sécurité nécessaires pour des charges de travail en production. Cela fait d’ArmoniK une solution idéale pour les organisations cherchant à faire évoluer efficacement leurs environnements de calcul haute performance dans le cloud.
Conclusion
ArmoniK sur AWS se distingue comme une solution puissante pour le calcul haute performance et à haut débit. Sa capacité à distribuer dynamiquement des graphes de tâches, à supporter plusieurs langages de programmation et à fournir une tolérance aux pannes robuste garantit qu’il peut gérer efficacement des charges de travail computationnelles complexes. Avec des benchmarks montrant jusqu’à 99,3 % d’utilisation des workers et un débit dépassant les 4 000 tâches par seconde, ArmoniK offre des performances exceptionnelles tout en optimisant l’utilisation des ressources. De plus, son intégration profonde avec les services AWS en fait un choix fiable et économique pour les organisations souhaitant faire évoluer leurs environnements de calcul dans le cloud.
En résumé, cette analyse approfondie montre qu’ArmoniK n’est pas seulement une merveille technique — c’est une solution pratique et évolutive prête à répondre aux exigences modernes du calcul.



